https://www.sciencedirect.com/science/article/pii/S2001037020302919?via%3Dihub
https://doi.org/10.1016/j.csbj.2020.05.026
Financial support: Ministerio de Economía y Competitividad (MINECO)

Abstract
Protein aggregation is a widespread phenomenon that stems from the establishment of non-native intermolecular 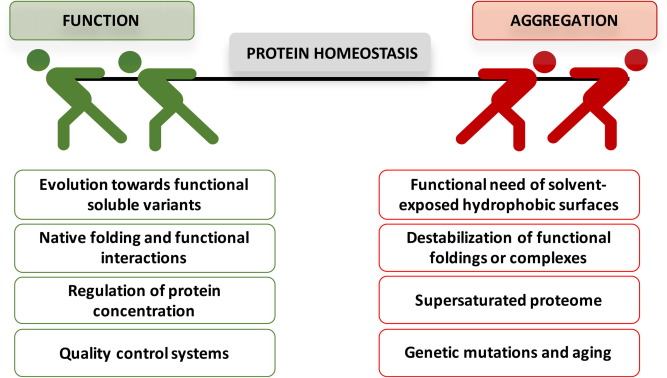 contacts resulting in protein precipitation. Despite its deleterious impact on fitness, protein aggregation is a generic property of polypeptide chains, indissociable from protein structure and function. Protein aggregation is behind the onset of neurodegenerative disorders and one of the serious obstacles in the production of protein-based therapeutics. The development of computational tools opened a new avenue to rationalize this phenomenon, enabling prediction of the aggregation propensity of individual proteins as well as proteome-wide analysis. These studies spotted aggregation as a major force driving protein evolution. Actual algorithms work on both protein sequences and structures, some of them accounting also for conformational fluctuations around the native state and the protein microenvironment. This toolbox allows to delineate conformation-specific routines to assist in the identification of aggregation-prone regions and to guide the optimization of more soluble and stable biotherapeutics. Here we review how the advent of predictive tools has change the way we think and address protein aggregation.
contacts resulting in protein precipitation. Despite its deleterious impact on fitness, protein aggregation is a generic property of polypeptide chains, indissociable from protein structure and function. Protein aggregation is behind the onset of neurodegenerative disorders and one of the serious obstacles in the production of protein-based therapeutics. The development of computational tools opened a new avenue to rationalize this phenomenon, enabling prediction of the aggregation propensity of individual proteins as well as proteome-wide analysis. These studies spotted aggregation as a major force driving protein evolution. Actual algorithms work on both protein sequences and structures, some of them accounting also for conformational fluctuations around the native state and the protein microenvironment. This toolbox allows to delineate conformation-specific routines to assist in the identification of aggregation-prone regions and to guide the optimization of more soluble and stable biotherapeutics. Here we review how the advent of predictive tools has change the way we think and address protein aggregation.